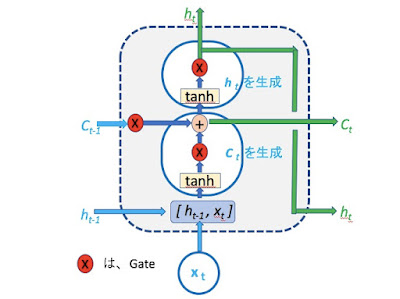
英語と日本語の差異から見るGoogle翻訳
Google翻訳は、どんな点が改善されたのか? ちょっと使ってみると、新しいGoogle翻訳が、飛躍的に能力を向上させたのは、感覚的には、明らかに見える。ただ、Google翻訳が実現した「飛躍」が、どのようなものかを正確に述べるのは、意外と難しい。翻訳の評価でよく利用されるBLEU等のスコアは、翻訳改善の重要な目安にはなるのだが、それは、あくまで量的なものだ。質的な「飛躍」は、その数字には、間接的にしか反映していない。 ここでは、英語と日本語の文法の差異に注目して、その差異が、Google翻訳では、どのように埋められているかを、いくつかの具体例で見てみよう。それらは、日本語・英語翻訳の中心的課題であるにもかかわらず、以前の機械翻訳技術では、うまく扱えていなかった。 また、日本語特有の言い回しでも、大きな改善が見られる。 日英文法の違いを考える 最初に、ChomskyのPrincipals and Parameters 理論に従って、日英文法の特徴的な違いを三つほど取り上げよう。 Head-directionality parameter 一つは、日本語・英語の語順に関するものだ。Head-directionality parameter といわれるものだ。 head-initial English eat an apple a person happy about her work I live in Takasu village. any book We saw that Mary did not swim head-final 日本語 リンゴを 食べる 彼女の仕事を喜んでいる 人 僕が、高須村 に 住んでいる どんな本 も マリーが泳がなかった のを みた Null-subject Parameter 二つ目は、Null-subject Parameter といわれるもの。日本語は主語の省略を許すが、英語はそれを許さない。 Null-subject Parameter (+) 日本語 Null-subject Parameter (-) English 私達は買い物をした。後でご飯を食べた。 We went shopping. Afterwa