「Zero-Shot 論文」の翻訳
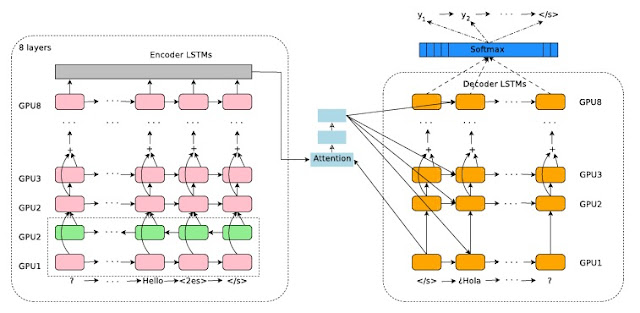
ゼロ・ショット翻訳を可能にする Googleの多言語ニューラル機械翻訳システム Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat melvinp, schuster, qvl, krikun ,yonghui,zhifengc,nsthorat@google.com Fernanda Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, Jeffrey Dean 概要 私たちは、単一のニューラル機械翻訳(NMT)モデルを使用して、複数の言語どうしを翻訳する、シンプルで洗練されたソリューションを提案します。 私たちのソリューションでは、基本のアーキテクチャーからモデルのアーキテクチャーを変更する必要はありません。代わりに入力文の始めに特殊な人工的なトークンを導入して、必要なターゲット言語を指定するだけです。エンコーダ、デコーダ、アテンションを含むモデルの残りの部分は変更されず、すべての言語で共有されています。 共有ワードピースのボキャブラリを使用することで、多言語NMTはパラメータを増やさずに、単一のモデルを利用することができるのです。これは、従来の多言語NMTの提案よりも大幅に簡単なものです。私たちの方法は、多くの場合、モデル・パラメータの総数を一定に保ちながら、関連するすべての言語ペアの翻訳品質を改善します。 WMT'14のベンチマークでは、単一の多言語モデルが、英語 -> フランス語翻訳に匹敵するパフォーマンスを達成し、英語 -> ドイツ語の翻訳では、最先端の結果を凌駕しています。同様に、単一の多言語モデルは、それぞれ、フランス語 -> 英語とドイツ語 -> 英語のWMT'14とWMT'15ベンチマークの最新の結果を上回りました。 製品版のコーパスでは、最大12言語対の多言語モデルで、多くの個々のペアの翻訳より良い翻訳が可能になります。 我々のモデルは、モデルが訓練された言語ペアの翻訳品質を向上させることに加えて、訓練中に明示的には見られなかった言語