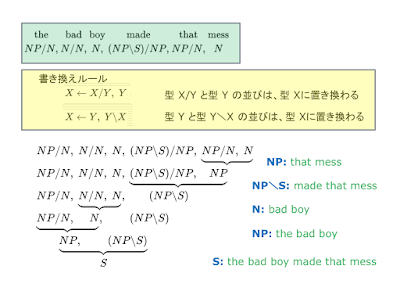
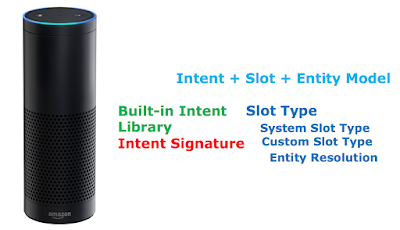
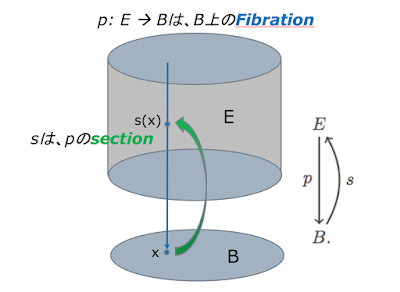
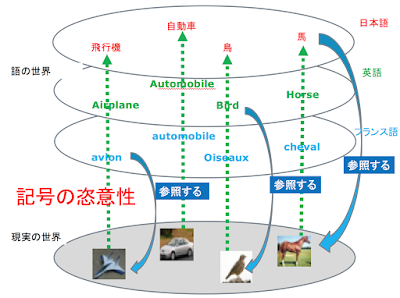
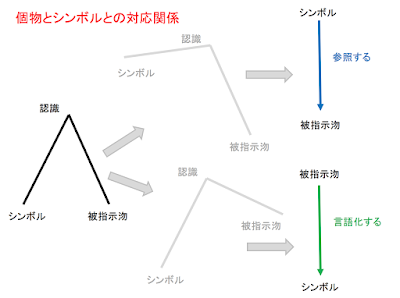
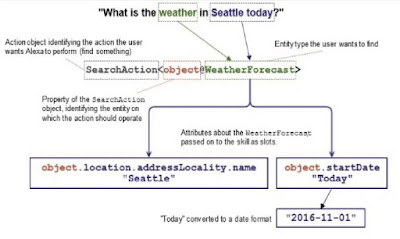
マルレク・ネット動画配信のお知らせ

5月22日開催のマルレク2018 第一回「ポスト・ディープラーニングの人工知能技術を展望する」を収録した動画のネット配信が始まりました。オープニングの部分は、無料で視聴できます。ご利用ください。 https://crash.academy/class/278 講演資料は、こちらからダウンロードできます。 https://goo.gl/jU54FM ------------------------------------ これまでのマルレク・ネット動画公開の情報です。 ------------------------------------ 2018/05/22 「ポスト・ディープラーニングの人工知能技術を展望する」 動画: https://crash.academy/class/278 資料: https://goo.gl/jU54FM 2018/1/15「ボイス・アシスタントから見るAIの未来」 動画: https://crash.academy/class/203 資料: https://goo.gl/i1V7Et 2017/11/30「量子コンピュータとは何か? 」 動画: https://crash.academy/class/189 資料: https://goo.gl/muA5TU 2017/9/28 「エントロピーと情報理論 -- 量子情報理論入門」 動画: https://crash.academy/class/156 資料: https://goo.gl/cu8F2r 2017/7/31 「人工知能の歴史を振り返る 」 動画: https://crash.academy/class/139/ 資料: https://goo.gl/6MeZJh 2017/5/28 「ニューラル・コンピュータとは何か? 」 動画: https://crash.academy/class/101/ 資料: https://goo.gl/qZyLQD 2017/3/27「Googleニューラル機械翻訳 」 動画: https://crash.academy/class/76/ 資料: https://goo.gl/X72wnM 2017/2/22「RNN と LSTMの基礎」 動画: http