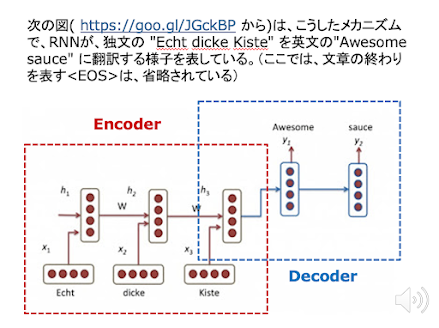
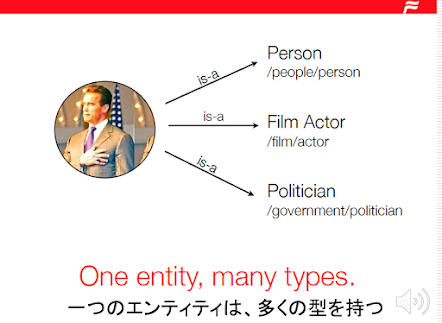
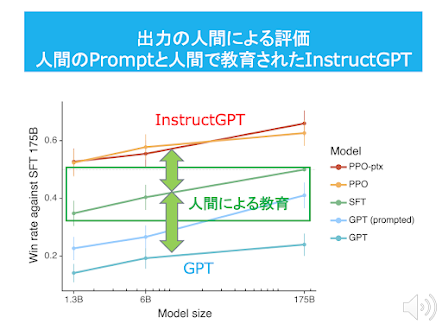
10/29 マルレク講演ビデオビデオ公開

【 10/29 マルレク 「エンタングルする自然 ver 2.0 」講演ビデオ公開しました 】 MaruLaboでは、以前に行ったセミナーの動画を定期的に公開しています。 今回は、昨年の10月29日に開催した、 マルレク 「エンタングルする自然 ver 2.0」の講演ビデオの公開です。 2022年のノーベル物理学賞は、アラン・アスペ、ジョン・クラウザー、アントン・ツァイリンガーの三人に与えられました。三人は、いずれも「エンタングルメント=量子もつれ」にかかわる実証的な実験の分野で大きな仕事をしてきた人たちです。
三人のノーベル賞受賞をきっかけに、量子の世界の不思議な現象である「量子エンタングルメント」に対する関心が高まることを期待しています。 エンタングルメントは、現代では量子の世界ひいては自然のもっとも基本的な現象だと考えられています。今回のセミナーでは、「エンタングルする自然」という新しい自然観の成立を、一つのドラマとして紹介したものです。 講演資料(ロング・バージョン)は、ところどころ細かい計算が入っていますが、セミナーでの講演自体では、それらは省かれています(講演資料ショート・バージョン)。 細かなことは置いといても、「逆理から原理」という、このドラマのあらすじを追いかけてもらえればと思います。 このドラマの主人公である John Bell は、20世紀最大の物理学者の一人だと思うのですが、ノーベル賞を貰うことなく突然の病で亡くなります。 ビデオに収録した「Bellの定理のブルース」はBell自身が制作にコミットしたものです。彼はきっと面白い人だったことがわかるような気がします。ここだけでも、聞いてくださいね。 ------------------------- 10/29 マルレク 「エンタングルする自然 -- 逆理から原理へ ver 2.0 」の講演ビデオの再生リストの URL です。 https://youtube.com/playlist?list=PLQIrJ0f9gMcOANd2Hfx7h0Pa5mDTglhby この再生リストは、次の四つのビデオを含んでいます。 ● はじめに + Part 1 「エンタングルメントの発見」 https://youtu.be/MhlljMtFPqI?list=PLQI...