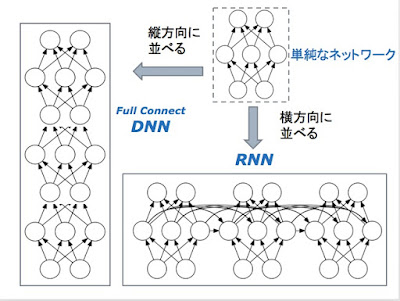
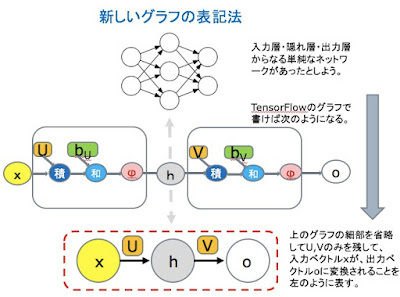
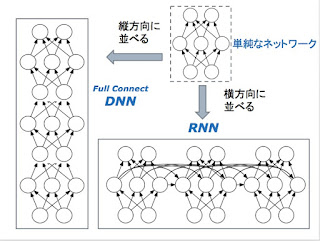
TensorFlow Foldについて
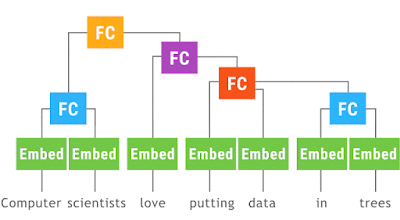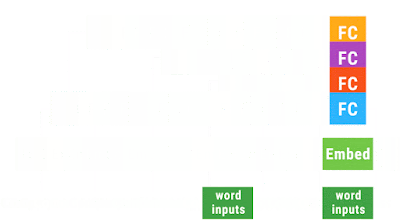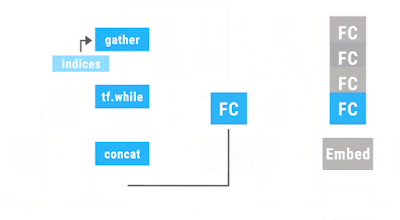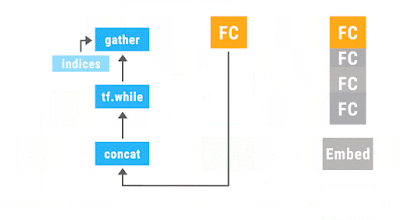
Googleが、TensorFlow Foldというライブラリーを発表しました。 "Announcing TensorFlow Fold: Deep Learning With Dynamic Computation Graphs" (論文は、 こちら ) この図の意味について簡単に説明したいと思います、 "computer scientists love "という文は、文字列あるいはwordのSepquence として見ることができます。普通のRNNやLSTMでは、こうしたSequenceとして入力を受け付けます。 ただ、先のSequenceは、文法的な構造を持っています。"computer scientists"が主語(節)で、"love"が動詞、"putting data in trees"が目的語(節)です。 構文の構造は、((Cpmputer scientists) (love ((putting data) (in tree)))) こんな感じですね。 ただ、先の文字列をSequenceとして入力すると、そうした文法構造の情報は、皆、失われます。それでは、文の持つ情報を正しく引き出すことはできません。 と言って、一つの文ごとに、その文法構造に対応したニューラルネットを構築していたのでは、沢山の文を解析するには、沢山のニューラルネットを構築しないといけなくなります。 一つのモデルで、SGDのバッチを回すというやり方だと、個々にモデルが違うような場合には、うまく、バッチの処理ができません。 この図では、次のようなプログラムが中心的な役割を果たしています。キャプチャーのタイミングが悪くて、図が書けていますが、本当は、単純なループです。 先の図と、この図を足したものが、本当のプログラムに近いかな。 先のデータ((Cpmputer scientists) (love ((putting data) (in tree)))) ですが、データの結合がわかりやすいように、色をつけます。(オレンジ (青 Cpmputer scientists) (紫 love ((赤 pu