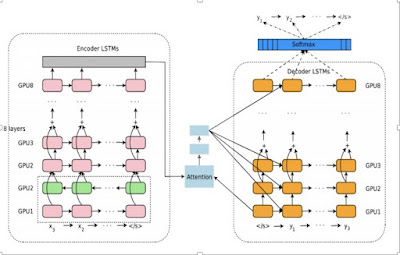
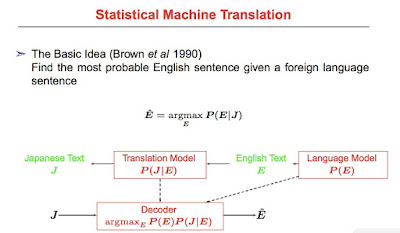
4月、東京・大阪で6時間集中講義
4月22日東京、4月29日大阪で、角川アスキーさんの主催で、「IT技術者の新しい常識「ディープラーニング」入門」6時間集中講義を行います。皆さんの参加をお待ちしています。 --------------------------------------------------- 4月22日の東京は、昨年来のシリーズの第二弾で、今回のテーマは、「自然言語とニューラルネットワーク」です。 次のような構成になります。 第一部 概説 自然言語と人工知能 第二部 RNNとLSTMの基礎 第三部 Googleニューラル機械翻訳 4月22日東京の開催趣旨はこちら https://goo.gl/LJ7qvA 申し込みページはこちらです。https://goo.gl/uHFcxj --------------------------------------------------- --------------------------------------------------- 4月29日の大阪のテーマは、「ニューラルネットワークの基礎」です。(4月22日の東京とは、コンテンツが異なりますのでご注意ください。) 次のような構成となります。 第一部 ニューラルネットワークの基礎 第二部 ニューラルネットワークはどう「学習」するのか 第三部 ニューラルネットワークによる画像認識技術 開催趣旨はこちら https://goo.gl/ufQ2vH 申し込みページはこちらです。https://goo.gl/xhXoqC --------------------------------------------------- --------------------------------------------------- 4/22 東京 開催概要 --------------------------------------------------- ■セミナータイトル: IT技術者の新しい常識「ディープラーニング」入門6時間集中講義 Part 2 自然言語処理とニューラルネットワーク ■講義の構成: 第一部 概説 自然言語と人工知能 第二部 RNNとLSTMの基礎 第三部 Googl