「ホットな議論」と「クールな議論」
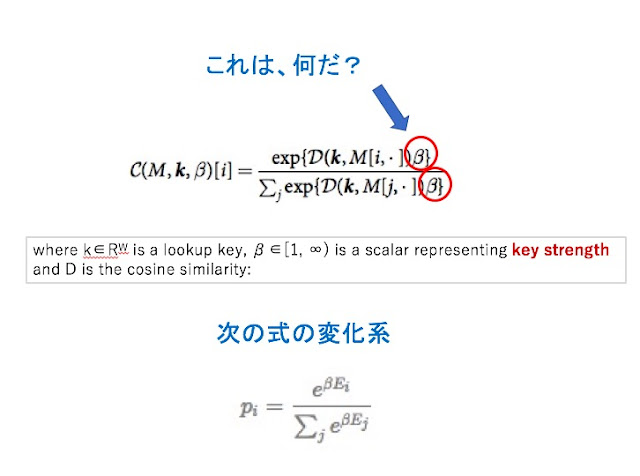
ディープ・ラーニングの「学習」では、様々な「メタ・パラメーター」が登場する。このパラメーターの設定で、学習の精度やスピードが、大きく変わることがある。 こうしたメタ・パラメーターの一つに「温度」が登場することがある。大抵は、Softmaxに確率分布を放り込む時に、一律に一定の定数をかける処理をすることがあるのだが、その定数を「温度」ということがあるのだ。 最初は、この言葉づかいが、奇妙に思えたのだが、昨日見たように、Softmax自体が、物理の理論を借用しているのだと思うと、こうした言葉遣いには、何の不思議もない。頭隠して尻隠さずだ。 最近見かけた例では、GoogleのDeep MindチームのDNC (Differentiable Neural Computer)に、次のような関数が定義されていた。(図1) この関数 C(M, k, β) [i] は、DNCで、もっとも基本的な関数の一つである。ご覧のように、分子でも分母でも、冪乗部分に一律に定数βがかかっている。Nature誌の解説では、このβは、「キーの強さ」だとされている。 でも、この式は、Softmaxの原型である図1の下の式、すなわち、ある分配関数が定義された時、系がある状態i を取る確率を表す式の変化系だと思うのがいいような気がする。 図2に、 β = 1/kBTと、明示的に温度Tが見える形にした時、Tの値をあげたり下げたりした時、この分布がどう変化するかを示してみた。(Ei の分布は変わらないとして) ディープ・ラーニングの学習でのメタ・パラメーター「温度」の役割についても、この関係は基本的に成り立つはずだ。 要するに、「温度」が高いと、いろんなところに複数の比較的高い確率が見られるようになり、「温度」が低いと、一つのピークがはっきりと現れる。(山の凸凹のパターンは、基本的に同じなのだが、コントラストが強調される) 特徴抽出には、後者の方が良さそうに見えるかもしれないが、意外と単純ではない。前者のほうが、収束には時間がかかりそうだが、思いもかけない特徴を発見する可能性があるかもしれないし、後者の方は、実は、つまらない特徴しか見つけられないということになるのかもしれない。 面白いのは、我々の日常の議論にも、こうした類型的には二つのパターンがあるのではないか



