arXiv 異聞
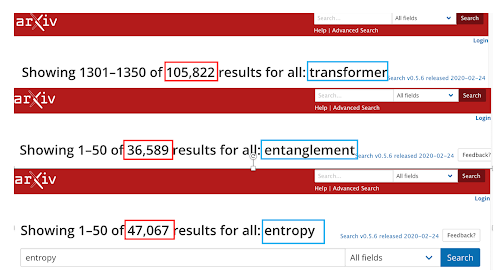
【 arXiv 異聞 】 僕は、arXiv が好きです。arXivがなかったら、今のような生活のスタイルは なかったと思っているくらいです。 普段は、arXivの検索は著者を探すのに使っています。優れた研究者の論文のリストは、研究の足跡がわかって、とても役に立ちます。 休み明け、いつもと違う検索をしました。野暮用でTransformer がらみの論文をarXivで探してみたのですが、8月ひと月だけでTransformerでヒットする論文 1,000本以上ありました。TransformやTransfomation は一般的な用語なのでその分差っ引いてみなければいけないのですが、それでも多いです。 驚いたのは、arXiv 全体では、Transformerで10万件以上ヒットすることです。Transfornerの基本的論文 "Attention Is All You Need" が出たのは、せいぜい 5-6年前だと思いますので、これは異常と言っていいくらいかも。 ちなみに、僕が興味を持っている Entanglement は 3万6千件台、Entropy は 4万7千件台でした。これらの概念は、科学の世界で、Transformerとは比較にならないほど長い間使われ研究されてきたものです。 さすが「産業革命以来の ... 」 僕はあまのじゃくなので、... まあ、色々思うところ、言いたいことはあるのですが、それは老後の楽しみにとっておくとして、今回は数字だけ。 休み明けに、8月にarXivに投稿された Transformer でヒットした論文の abstract 集を作りました。興味がある方、ご利用ください。 https://drive.google.com/file/d/17MBaT-Zl1jzLMVjpm5fjR_bCkvguhcAF/view?usp=sharing
