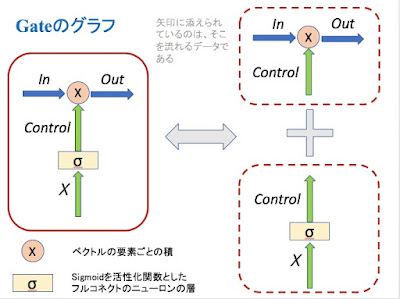
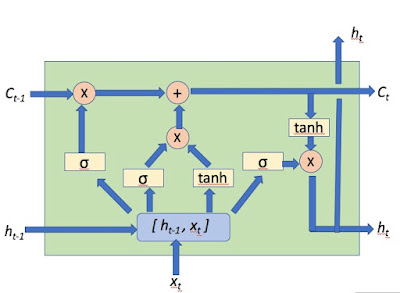
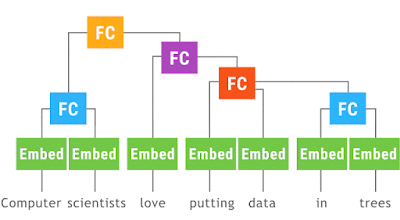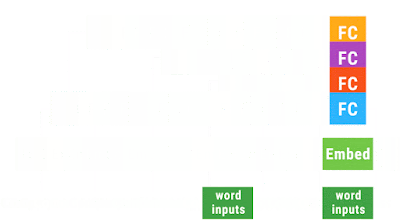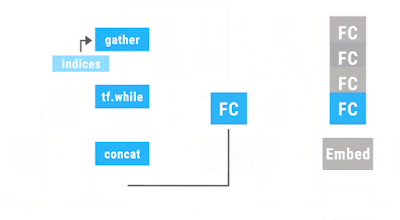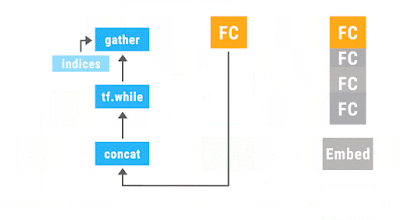
TensorFlow 1.0リリースと TF Dev Summit 2017 でのJeff Deanのキーノート

2月15日、TensorFlow 1.0をリリースした、TensorFlow Developers Summit 2017 のキーノートの様子です。 冒頭のスピーチは、もちろん、Jeff Dean。タイトルは、「TensorFlow : ML for Everyone」 みんなのための機械学習ですね。 TeasorFlow登場以前の、「第一世代」の"DistBelief" の話から始まります。2012年の「Googleの猫」で有名なシステムですね。スケーラブルで実際に製品版として動いていたんだけど、GPUもCPUもハードは固定されていて柔軟ではなかったと。RNNや強化学習にも使えなかったと。 それと比べると、「第二世代」のTensorFlowは、多くのプラットフォームをサポートして(Rasberry Piの上だって動く)、その上、Googleのクラウド上でも動く(それにもたくさんの方法がある)。 そして、TensorFlowは、Pythonを始め、C++, Java, Go, Haskell, R と、多くの言語をサポートしている。(Haskellでも動くんだ、知らなかった。もっとも最近出た Fold は、関数型プログラミングそのものだからな。) TensorFlowの大きな特徴は、TensorBoardのような、Visualizationの優れたツールを、一緒に提供していること。 TensorFlowは、また、Google自身の内部でも、検索、Gmail、翻訳、地図、Android、写真、スピーチ、YouTube ... 様々な分野で、急速に利用が進んでいる。 オープンソースのTensorFlowの開発は、GitHubの機械学習の分野では、ナンバーワンのレポジトリーの数を占めている。 機械学習の様々なフレームワークの中でも、TensorFlowが、圧倒的に利用されている。 GitHubでのStarの数は、 TensorFlow 44508 scikit-lean 16191 Caffe 15690 CNTK 9383 MXNet 7896 Torch