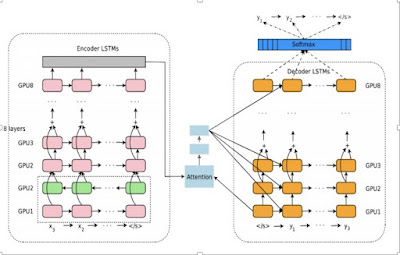
Google翻訳のアーキテクチャー(3) Attention Mechanism

新しいGoogle翻訳の元になった論文 新しいGoogle翻訳のシステムは、全く新しいアイデアに基づいてスクラッチから作り上げられたものではない。 その基本的なアイデアは、2016年の5月にarXivに投稿された次の論文に多くを負っている。(Google Brainのチームが、新しいシステムを6ヶ月で仕上げたと言っていることと、符合する。) Bahdanau, D., Cho, K., and Bengio, Y. “Neural machine translation by jointly learning to align and translate” https://goo.gl/HZxbNH 「近年、ニューラル機械翻訳として提案されたモデルは、多くの場合、Encoder-Decoderのファミリーに属している。そこでは、ソースの文が固定長ベクトルにエンコードされ、そこからデコーダが 翻訳文を生成する。この論文では、固定長ベクトルの使用が、この基本的なEncoder/Decoderアーキテクチャの性能を改善する上でのボトルネックになっていると推論し ... 」 先に見た、Ilya Sutskever らの翻訳システムでは、翻訳されるべき文は、Encoderで、一旦、ある決まった大きさの次元(例えば8000次元)を持つベクトルに変換される。このベクトルからDecoderが翻訳文を生成する。入力された文が、長いものであっても短いものであっても、中間で生成され以降の翻訳プロセスすべての出発点となるこのベクトルの大きさは同じままだ。このシステムでは、長くても短くても入力された文全体が、一つの固定長のベクトルに変換されるのだ。 確かに、そこは翻訳の精度を上げる上でのボトルネックになりうる。事実、Ilya Sutskever らのシステムでは、文の長さが長くなるにつれて、翻訳の精度が低下されるのが観察されるという。 それでは、どうすればいいのか? 「モデルに自動的に、ターゲット・ワードを予測するのに重要なソース・文の一部分について、 (ソフト)検索を可能とすることによって、これを拡張することを提案する。その際、これらの部分を明示的にハードセグメントとして形成する必要はない。」 Attention