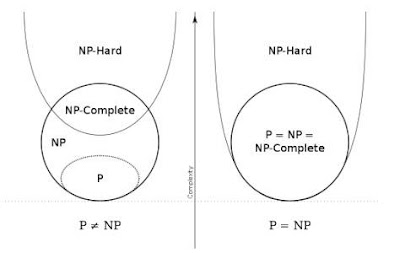
エントロピーと情報
エントロピーという概念が、情報の概念と結びついていることは、IT技術者ならどこかで聞いたことはあるかもしれない。でも、それがどういう繋がりなのかを説明できる人は、少ないように思う。 ただ、それにはいくつかの理由がある。 一つの理由は、高校までの授業で「熱」や「温度」「仕事」「エネルギー」については教えられるのだが、「エントロピー」は教えられることはない(多分)からだと思う。高校卒業後、「熱力学」の講義を受ける人は、多分、少数派だ。 その上、ITの仕事についても、一部の人(例えば、通信関係の人)を除けば、プログラミングを始めても、情報量やエントロピーの概念が必要となることは、ほとんどないと言っていい。 ただ、そのままでいいかというと、本当は、よくないのではと、最近、僕はは思うようになっている。 自然を理解するのに、「エネルギー」と「エントロピー」は、二つのキー・コンセプトだと思うようになったからだ。といっても、子供達に「エントロピー」をどう教えればいいのか、具体的なプランがあるわけではないのだが。 ただ、状況は、少しずつ変化してきているのは事実だ。 以前の投稿でも書いたが、ディープラーニングでは、コスト関数に「クロス・エントロピー」が登場するし、クラス分けのSoftMax関数を理解するには、分配関数の知識があった方が見通しが良くなる。 また、セキュリティーの基礎としての「暗号化」の技術には、「ランダムネス」や「一方向関数」の概念が使われている。これらは、みな、エントロピーの議論と結びつく。 エントロピーと情報の概念が結びつきにくいのは、もう一つ大きな理由があるように思う。それは、エントロピーの概念が、歴史的に様々に変化してきたからだ。当初は、それは情報の概念とは、無関係だった。 Entropy という言葉は、19世紀半ば(1856年?)に、Clasiusによって名付けられた。それは、「熱」や「温度」「仕事」「エネルギー」といった量に関連づけられ、「熱力学」の中で生まれた概念であった。 Wattの最初の蒸気機関が完成したのは、1776年。熱力学の基礎を作ったCarnotの仕事は、1828年である。彼らの実践的関心は、産業革命を可能にした当時の最先端技術である「蒸気機関」の効率化に向けられていた。 彼らは、蒸気機関に熱と