Aaaronsonのコメント
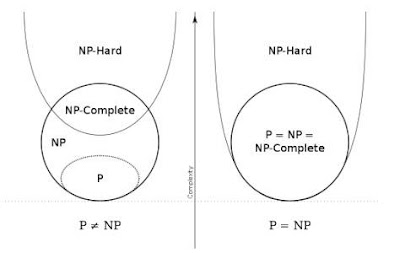
Scott Aaronsonが、短いコメントを出した。 「P≠NPの証明のこと、僕に聞くのはやめて。あの証明が、なりたっていない方に20万ドル賭けてもいい。 ... 今週末までに、反証されていなければ、僕を、心を閉ざした馬鹿者と呼んでいいよ。」 てんで、信じてないみたい。元気なので安心した。 To everyone who keeps asking me about the “new” P≠NP proof: I’d again bet $200,000 that the paper won’t stand, except that the last time I tried that, it didn’t achieve its purpose, which was to get people to stop asking me about it. So: please stop asking, and if the thing hasn’t been refuted by the end of the week, you can come back and tell me I was a closed-minded fool.