角川連続講座 第三回「人工知能と量子コンピュータ」
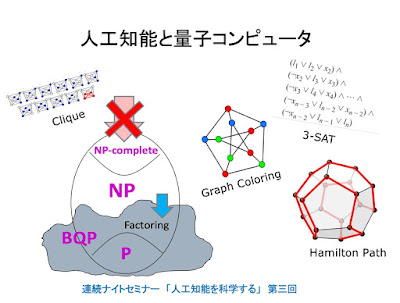
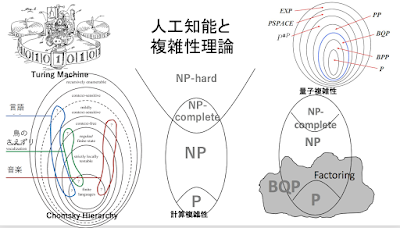
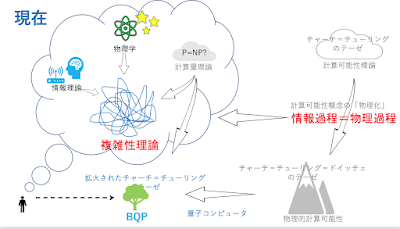
あさって 11/19のセミナーですが、「はじめに」の部分できました。(遅い!)遅かったせいか、まだ、席に余裕があります。よろしかったら、聴きに来てください。 https://lab-kadokawa71.peatix.com/ 資料公開しました。ご利用ください。 https://goo.gl/ymYfFY --------- はじめに --------- 人工知能のもっとも基本的な問題の一つは、機械と人間にとっての「認識」の限界を正確に知ることであると僕は考えている。 量子コンピュータの登場が、こうした問題にどのような新しい地平を切り開くのかということは、人工知能論にとっては大事な問題である。 こうした観点から、量子コンピュータと量子複雑性理論については、これまでいくつかの機会で紹介してきたのだが、計算可能性理論や複雑性理論そのものについては、あまり語ってこれなかった。 今回は、第一部で、改めて複雑性理論の中核である「NP-完全」問題という不思議なコンセプトを説明しようと思う。「NP-完全」の発見なしには、複雑性理論は生まれなかったと言っていい。その理論的インパクトは、計算可能性理論の創出にゲーデルの不完全性定理が与えたインパクトと同じものだと思う。 「NP-完全」問題は、基本的に、力まかせの総当たりでやれば必ず解は見つかるはずというところが、どう頑張っても原理的に証明することが不可能な命題が存在することを主張する「不完全性定理」とは異なっている。 ただ、総当たりで問題を解くには、n個の条件が成り立つか否かというように問題を単純化しても、試すべき条件の組み合わせは、2のn乗個になる。nが小さいうちは(例えば、n=10なら、1024個の場合をチェックすればいい)なんとかなるのだが、nが大きくなるにつれ、問題は、文字通り指数関数的に難しくなる。それは、総当たり法では、現実的には、全く手に負えない問題となる。 量子コンピュータに対する期待の一つは、それがn-qubitの入力に対して、それに対応する2のn乗個の状態の演算を同時に実行することができるので、それをNP-完全問題の攻略に利用できるのではないかというものである。 量子コンピュータなら、NP-完全問題も解けると思っている人も少なくないのだが、